引论
下面的几篇要集中整理一下排序算法。排序算法有很多种,思想各不相同,时间复杂度也不一样。这里先对要排序的数据做一些约束:
待排序的数据存放在数组中,且索引为从0开始
待排序的数据均为整数
之所以有这两个约束是为了简化算法,非整数数据只需做些许改动即可应用。下面介绍一种相当简单的排序——插入排序
插入排序
思想:对于N个待排序的数据,插入排序一共需要N-1次排序过程(pass)。即P=1,… , N-1,对于第P次排序过程,插入排序保证从位置0到位置P的数据是已排序的。也就是说前P个数据是排好序的,我们只需要将第P次过程所要插入的数据(第P+1个)插入到它应该在的位置就好了。
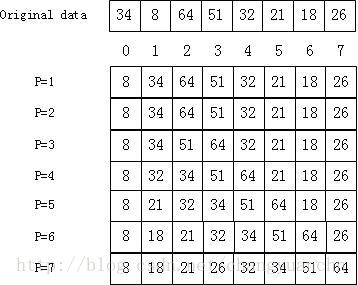
当进行P=1的过程时,因为只有34一个元素,所以必然是前P个元素是排好序的,那么我们需要插入元素8,因为8<34,故8要移动到34的前面,因此当P=1的过程结束时,前面的数据(8,34)必定是排好序的,同理对于P=2,我们要插入64,也就是说要把64移动到合适的位置(位置0,1,2),由上图可知,64为(8,34,64中)最大的元素,位置不动。同理其他排序过程。因此插入排序的排序过程所利用的就是前面的排好序的数据。
C语言代码实现
1 | void InsertSort(ElementType A[],int N) |
时间复杂度
因为两层嵌套循环,因此插入排序的时间复杂度为O(N^2)。
更准确的话,应该是:
简单排序算法的一个下界
首先引入一个叫做逆序的概念:数组中具有性质$ i
因此我们可以有如下的一个结论
- 对于N个互不相等的数,他的逆序的个数的均值为$ \frac{N(N-1)}{4} $。
这个的证明比较简单,对于任意的一个互不相等数组$L$,这个数组的倒序数组为$L_r$,这两个数组的逆序的总和为$ \frac{N(N-1)}{2} $。也就是说任意两个数据必然存在一个逆序,不是在$L$中就是在$L_r$中。因此每个数组的逆序的个数的均值为$ \frac{N(N-1)}{4} $。
- 交换相邻元素的排序方法的平均时间复杂度为$ \Omega(N^2) $
这个的证明也比较简单,我们知道排序时的交换次数等于逆序的个数,而逆序的均值为$ \frac{N(N-1)}{4} $。因此平均时间复杂度为$ \Omega(N^2) $
- 如果我们想以亚二次的方法排序的话,就要交换距离较远的元素,也就是说一次交换要能够消除不止一个逆序,这样才能提高排序的效率。