引言
通常来说,机器学习根据训练数据是否有标签可以分为两类,一类是监督学习,也就是训练数据有标签,即给定输入,我们知道他属于哪一类,另外一种就是无监督学习,我们不知道他的标签是什么,对于数据应该怎么分类也所知不多。对于监督学习,有很多算法,包括神经网络啊,支持向量机啊等等。对于无监督学习,目前的手段并不多,主要是聚类,通过数据内部结构,将数据自动聚成几个类别,k-means就是聚类的代表算法之一。
多说一点,其实无监督算法才应该大力研究,因为现实世界中,有标注的数据毕竟是少数,大量的数据还是没有标签的,如果能通过算法将其自动聚类或者学习到相应的结构模型,那是很有意义的。
k-means是什么
所谓的k-means,又称之为k均值,简单的说就是将已有的非标注数据根据距离来度量彼此的相似性,将其自动聚类为k类。如下图所示:
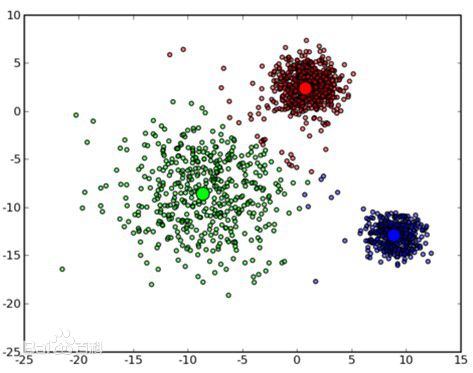
具体的算法也很简单,如下所示:
1) 从样本中随机选取K个值作为质心
2) 将剩余的样本数据计算其与质心的距离,并将其归类到最近的质心的类
3) 根据聚类结果,重新计算质心
4) 迭代直到质心不再变动或者小于指定阈值,算法结束。
可以看出,算法逻辑很简单,就是需要大量的重复的距离计算。
算法的优缺点
优点: 简单
缺点: 当数据量大时,计算量会非常大;同时K值的选取也是一个难题;随机初始划分也会导致聚类效果比较差。
算法的改进
因为有了上面的一些不足,因此业界也针对这些问题有了一定的改进
初始点的选取
一种方法是选择尽可能远的K个点。
或者先用层次聚类进行初始聚类,然后将聚类的中心点作为初始值,进行K-means聚类。
K值的选取
对于类簇来说,我们有下面的定义:
类簇的直径是指类簇内任意两点之间的最大距离。
类簇的半径是指类簇内所有点到类簇中心距离的最大值
如果通过不同的k值的选取,类簇的指标变化由剧烈变为平缓时,那么这个转折点一般就是最佳的K值选取点