引言
隐马尔可夫模型是关于时许序列的概率模型。是由一个隐藏的马尔科夫链随机生成不可观测的状态序列,然后由状态序列生成一个观测序列的过程。
每个状态生成一个观测,同时每个状态会转移到下一个状态。因此马尔科夫过程有两个关键的序列,一个是状态序列,一个是观测序列。
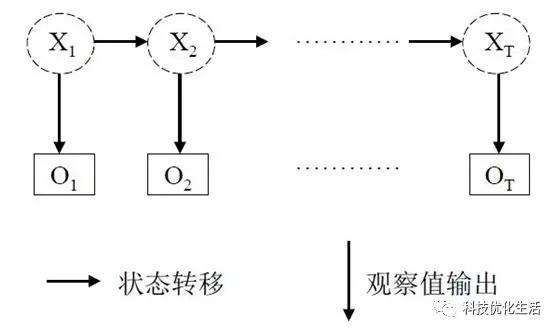
上图就是一个标准的马尔科夫过程的观测输出以及状态转移过程。
隐马尔科夫模型由初始概率分布,转移状态矩阵概率分布,观测状态概率矩阵确定。
假设我们的状态集合为
观测集合为
上面的两个集合是观测和状态的取值集合。
假设我们的markov过程的状态序列为
观测序列为
我们可以写出状态的转移矩阵,其中,
也就是从时间点状态转移到时间点状态的概率。
我们也可以写出观测矩阵,其中,
也就是从时间点状态的观测值为的概率。
再加上我们的初始概率,其中
因此本质上我们的markov过程受如下的参数控制:
隐markov过程需要满足的假设条件
1) 齐次马尔科夫假设
即
也就是时刻的状态只决定于时刻的状态,跟其他时刻的状态以及观测无关。
2) 观测独立性假设
即
也就是某一时刻的观测只与这一时刻的状态有关,跟其他时刻的状态以及观测无关。
不满足这两个朴素的假设条件,后面的一切推导都是错误的。
隐马尔可夫模型的三个基础问题
1) 概率计算
即给定参数和观测,计算,即某一观测序列出现的概率问题。
2) 学习问题
即已知,估计参数,即参数估计问题。
3) 预测问题
已知和观测,求使最大的状态序列,也就是能得到当前观测的最可能的状态序列。
下面我们就这三个问题,一个一个的解决
概率计算问题
概率计算就是计算,给定了,这个计算就是一个简单的算数问题。那么我们来看下直接计算:
直接计算
首先第一步,计算状态序列为时的概率为:
当状态序列为时,观测序列为时的概率为:
根据条件概率,可以得到:
对所有可能的状态求和,可以得到:
这样计算是可以的,但是这个计算量太大了,是阶的。
因此引入了前向算法和后向算法。这两个算法能有效的降低计算复杂度。
前向算法
首先定义前向概率:
前向概率表示时刻,部分观测序列为, 且时刻状态为的概率
前向算法:
初始值:
递推:
终止:
因此前向算法的本质就是计算前向概率,然后将其递推到全局
后向算法
首先定义后向概率
后向算法:
初始:
递推: 对于
终止:
后向算法的递推图示:
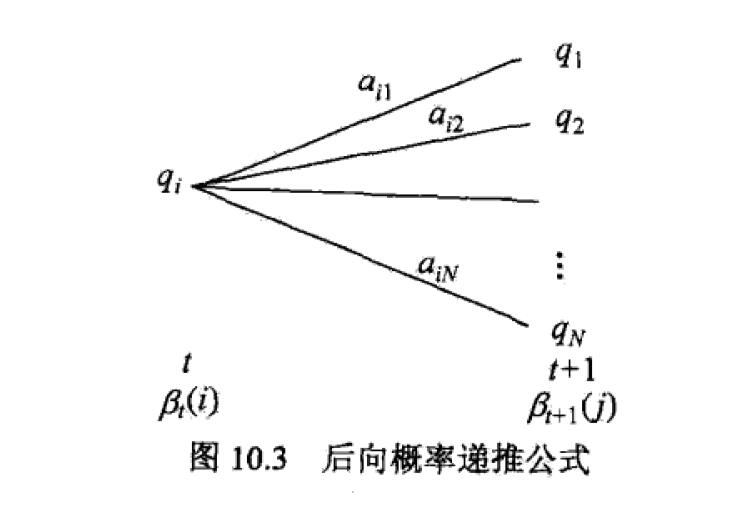
前向后向概率表示
利用前向后向概率可以得到:
推导如下:
则表示观测为,状态由转到的概率
则表示观测为,状态由转到的概率
则则 表示观测为,状态由转到的概率
对状态和状态求和,就可以得到
前向后向概率的几个特殊的统计值
- 定义给定参数的情况下,时刻处于状态的概率为:
则:
由前向概率和后向概率
可以得到:
于是可以得到:
定义给定参数的情况下,时刻处于状态且时刻处于状态的概率为:
而:
所以有:
这里我们之所以这么费事的要推导出这两个概率,是为了后面的预测算法做铺垫,后面会用到
参数估计
监督学习
上面我们推导了概率计算问题,那么下面我们就要来面对一个很机器学习的问题了,参数估计。给定数据,估计分布,这个是统计机器学习的主要内容。
首先如果我们已经知道了状态序列,那么这个参数估计就好办多了,直接统计值就行了,这种属于监督学习。
如果已知状态序列和观测序列为
则状态转移概率的估计:
其中为时刻处于状态且时刻转移到状态的频数
则观测概率的估计:
其中为状态观测为的频数。
可是现实生活中哪有这样好的事情,我们最长面对的情况是只拿得到观测,而拿不到状态,这时,我们看怎样处理
非监督学习
如果已知观测序列为,状态序列未知,估计参数。我们发现这正好是EM算法的能力啊,只要将状态作为隐变量,就可以用EM算法来解决这个问题了。
首先,我们知道
根据EM算法的步骤,首先我们需要写出完全数据的对数似然函数:
其中跟最优化无关,因此可以省略掉,因此完全函数可以写为:
而:
因此函数可以写为:
E步完成后,就该M步的了:
由于我们需要极大话的三个项,分别在上面的三个分式中,因此单独极大化上面的分式即可。
第一项:
参数满足的约束条件为,因此利用拉格朗日乘子法,可以得到拉格朗日函数
对其求偏导并令其结果为0,可以得到:
得到:
对i求和,可得:
带如到上式有:
同理,可以得到另外两项的估计,如下所示:
如果引入我们之前的统计量
那么参数估计可以写为:
预测问题
近似算法
所谓近似算法,就是每个时刻选择最优可能出现的状态,将她作为这个时刻的结果。
给定,有
则,每个时刻的最优可能的状态:
进而得到状态序列
近似算法简单,易于计算,但是这个不是最优的结果。其实我们的预测算法本质上就是一个最优路径的问题,因此可以引入动态规划的原理来解决,这就是Viterbi算法
Viterbi算法
输入: 和
初始化:
计算
更新参数
终止
最优路径回溯
对
总结
上面就是隐马尔可夫模型的三个基本问题以及相应的求解方式。本质上讲,隐马尔可夫模型比较简单,但是也比较常用,在分词,语音识别方面有着广泛的应用,不过由于深度学习横空出世,单纯的隐马尔科夫模型略显无奈啊。