算法思想
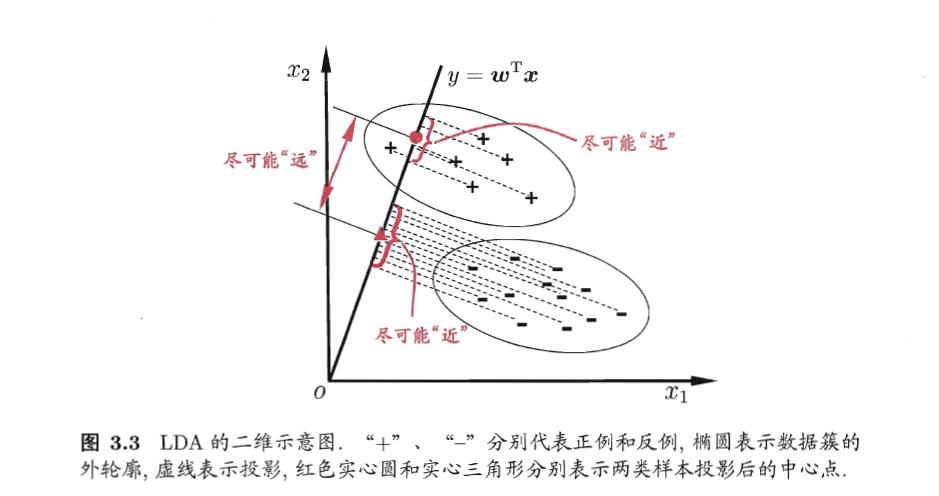
LDA是经典的有监督的降维方法。而我们的降维方法,一般都是将样本数据进行投射。LDA的思想就是将样本投射到一条直线上,使同类的样本点尽可能的接近,而异类的样本点尽可能的远离。如下图所示:
算法推导
假设我们的样本数据是 其中
我们假设分别为第类样本的集合,均值以及协方差矩阵。
我们将数据映射到w上,则两类样本的中心点在直线上的投影分别为
将所有的数据投射到w上,则两类样本的协方差分别为
根据LDA的思想:
同类的样本点尽可能的接近,而异类的样本点尽可能的远离
有:
式子要尽可能的小
式子要尽可能的大
因此我们的目标转化为最大化:
我们可以定义类内散度矩阵:
类间散度矩阵:
所以优化目标变为:
下面我们的目标就是如何确定w。
上面的式子与w的大小无关,因此问题可以转换为:
利用拉个朗日乘子法,有:
由于,因此可以令:
带如式子有:
对做奇异值分解:
所以有:
因此可以得到投影向量:
多维场景
对于降维问题,如果降到多维的场景,可以如下处理:
有:
因此只需要对做特征值分解,得到的最大的特征值对应的特征向量组成的矩阵就是多维的投影向量。
多分类场景
如果是多分类(假设为)问题,则只需要修改下式即可:
其中为第例样本的个数。
最后说一句
特征值分解或者奇异值分解无处不在啊。