Barrier,翻译是栅栏。是同一个queue中的command,或者同一个subpass中的command所明确指定的依赖关系。我们可以想象一下有一大串的command乱序执行(实际上可能是顺序开始,乱序结束),barrier就是在中间树立一道栅栏,要求栅栏前后保持一定的顺序,但是前后的内部之间的顺序它是不关心的。
从这里我们可看到Barrier是command之间(或者说是queue内,不能跨queue)的同步原语。由vkCmdPipelineBarrier来创建barrier,实际上从这个名字vkCmdPipelineBarrier也可以看出,它应用于command同步。
1)vkCmdPipelineBarrier
函数的参数看着很简单,但是他的内容的理解还是很复杂的。1
2
3
4
5
6
7
8
9
10
11VKAPI_ATTR void VKAPI_CALL vkCmdPipelineBarrier(
VkCommandBuffer commandBuffer,
VkPipelineStageFlags srcStageMask,
VkPipelineStageFlags dstStageMask,
VkDependencyFlags dependencyFlags,
uint32_t memoryBarrierCount,
const VkMemoryBarrier* pMemoryBarriers,
uint32_t bufferMemoryBarrierCount,
const VkBufferMemoryBarrier* pBufferMemoryBarriers,
uint32_t imageMemoryBarrierCount,
const VkImageMemoryBarrier* pImageMemoryBarriers);
commandBuffer指设置barrier的命令要写入的commandBuffer。
srcStageMask和dstStageMask 指定了barrier的同步范围,也就是说barrier作用在这两个之间(srcStageMask表示哪个阶段的管线最后写入数据,dstStageMask 表示那个阶段的管线接下来要从资源读取数据)。
dependencyFlags 高阶设置,目前还不太懂
memoryBarrierCount和pMemoryBarriers 应用全局的memory barrier
bufferMemoryBarrierCount和pBufferMemoryBarriers 应用于Buffer的 memory barrier
imageMemoryBarrierCount和pImageMemoryBarriers 应用于Image的memory barrier
2) VkPipelineStageFlags
下面我们来理解一下srcStageMask和dstStageMask。
我们知道GPU是一个高度流水线化的设备,实际上我们的command位于顶部,依次执行下面的各个阶段,执行完毕后,命令从管道底部退出。
当我们将多个command 依次放入到queue里面后,他们实际上是并行执行的,而如果他们之间存在依赖时,我们就没有办法控制他们的前后顺序了。假设我们有两个command,一个渲染shadow的renderpass,另一个是主流程的renderpass。假设我们需要设置的barrier如下:1
2
3
4
5vkCmdPipelineBarrier(
commandBuffer,
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT, // source stage
VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT, // destination stage
/* remaining parameters omitted */);
我们设置srcStageMask为ShadowPass里面的VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT阶段
dstStageMask为MainPass里面的VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT。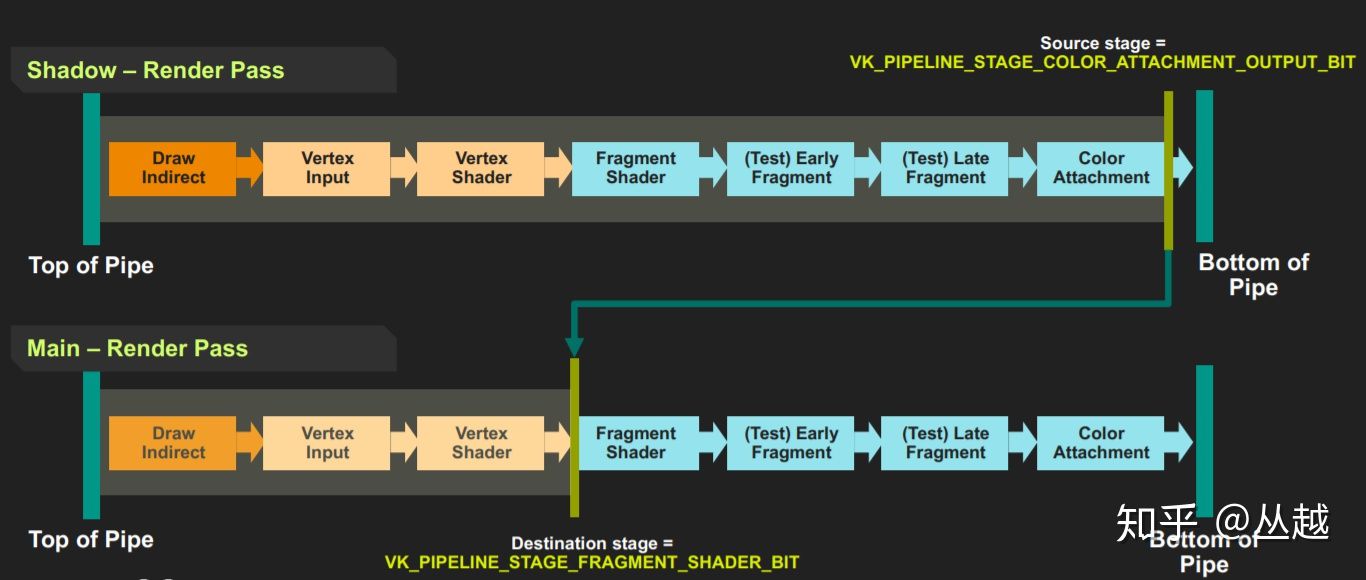
那也就意味着mainPass的fragment shader阶段一定要在shadowPass的color attachment阶段后执行。
这也就意味着mainPass的fragment shader之前的阶段可以和整个shadowPass并行,如下图所示。
实际上srcStageMask和dstStageMask之间的阶段越多,并行度越高,否则则并行度越低。
对于正常的管线阶段来说,我们有如下的阶段定义:1
2
3
4
5
6
7
8
9
10
11
12
13
14VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT = 0x00000001,
VK_PIPELINE_STAGE_DRAW_INDIRECT_BIT = 0x00000002,
VK_PIPELINE_STAGE_VERTEX_INPUT_BIT = 0x00000004,
VK_PIPELINE_STAGE_VERTEX_SHADER_BIT = 0x00000008,
VK_PIPELINE_STAGE_TESSELLATION_CONTROL_SHADER_BIT = 0x00000010,
VK_PIPELINE_STAGE_TESSELLATION_EVALUATION_SHADER_BIT = 0x00000020,
VK_PIPELINE_STAGE_GEOMETRY_SHADER_BIT = 0x00000040,
VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT = 0x00000080,
VK_PIPELINE_STAGE_EARLY_FRAGMENT_TESTS_BIT = 0x00000100,
VK_PIPELINE_STAGE_LATE_FRAGMENT_TESTS_BIT = 0x00000200,
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT = 0x00000400,
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT = 0x00000800,
VK_PIPELINE_STAGE_TRANSFER_BIT = 0x00001000,
VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT = 0x00002000,
当然上面的阶段有些可能是合并的,有些可能会丢失。
同时vulkan还定义了如下的三个伪阶段,他们组合了多个阶段或处理特殊的访问1
2
3HOST_BIT
ALL_GRAPHICS_BIT
ALL_COMMANDS_BIT
注意这里面有两个阶段TOP_OF_PIPE_BIT和BOTTOM_OF_PIPE_BIT,这是人为定义的两个阶段,表示开始和结束
当我们进行如下的设置时:1
2
3
4
5vkCmdPipelineBarrier(
commandBuffer,
VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT, // source stage
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, // destination stage
/* remaining parameters omitted */);
表示GPU上所有的命令都完成后,才开始转换,并且在转换完成之前,没有任何命令可以开始启动,这个障碍将等待一切完成,并阻止任何工作开始。这实际上是很低效的一种方式。
当我们进行如下的设置时:1
2
3
4
5vkCmdPipelineBarrier(
commandBuffer,
VK_PIPELINE_VERTEX_SHADER_BIT, // source stage
VK_PIPELINE_COMPUTE_SHADER_BIT, // destination stage
/* remaining parameters omitted */);
这里表示我们的vertex shader处理完成后(假设vertexShaderimageStore写入了数据),然后computer shader才能来读取。
参考资料:
https://zhuanlan.zhihu.com/p/100162469
https://gpuopen.com/learn/vulkan-barriers-explained/
http://themaister.net/blog/2019/08/14/yet-another-blog-explaining-vulkan-synchronization/
http://cpp-rendering.io/barriers-vulkan-not-difficult/