在场景中,我们需要设置一个camera,这样实际上只有在camera能够看到的物体,才能最终的渲染成图像,显示在屏幕上,就像人的眼睛一样。
要在场景中定义一个camera,对于camera来说,有两个主要的值,一个是位置,一个是方向。
当我们定义了位置后,方向也就有了(一般来说方向是camera的位置指向世界坐标的原点)。
假设我们有camera的位置信息如下:1
glm::vec3 cameraPos = glm::vec3(0.0f, 0.0f, 3.0f);
那么我们就可以定义camera的方向了:1
2glm::vec3 cameraTarget = glm::vec3(0.0f, 0.0f, 0.0f);
glm::vec3 cameraDirection = glm::normalize(cameraPos - cameraTarget);
在MVP矩阵的章节中,我们将物体从各自的局部空间变换到世界坐标空间后,还需要变换到观察空间,也就是以camera为主体的空间。这个空间就是以camera的位置为原点,来构建一个坐标系。有了这个坐标系,就可以通过相应的函数来构建这个View矩阵了。
首先我们有了cameraDirection,这样我们就有了一个坐标轴,然后我们可以定义一个向上的向量,这个向量可以是世界空间中的Y轴,这样有了两个向量,我们就可以利用向量的叉乘来得到一个右向量了,这个右向量与cameraDirection垂直。1
2glm::vec3 up = glm::vec3(0.0f, 1.0f, 0.0f);
glm::vec3 cameraRight = glm::normalize(glm::cross(up, cameraDirection));
有了方向向量和右向量,我们再次利用叉乘,就可以得到一个真正的上向量了。1
glm::vec3 cameraUp = glm::cross(cameraDirection, cameraRight);
这样我们就有了三个互相垂直的向量,也就是camera的空间已经建立起来了。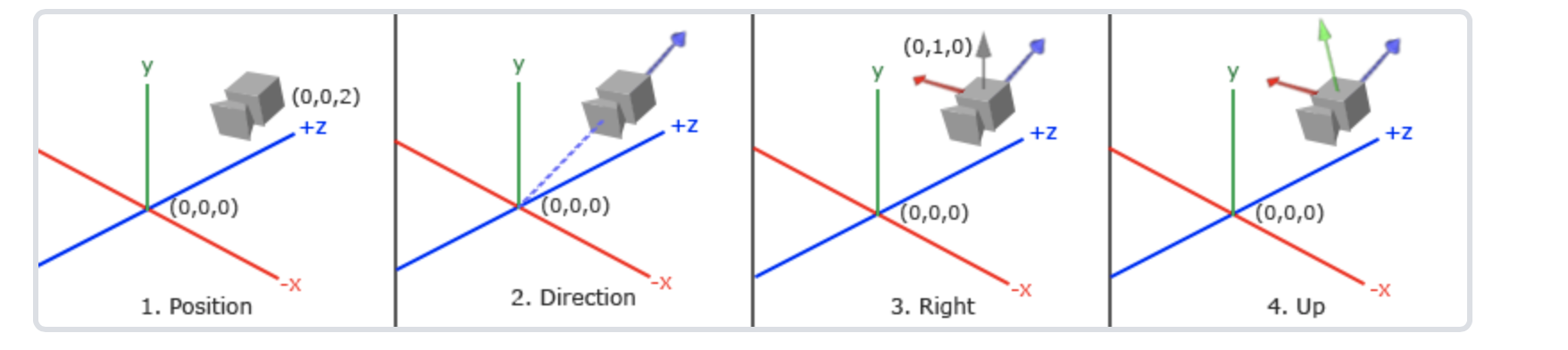
因此我们就可以得到相应的View矩阵,如下所示: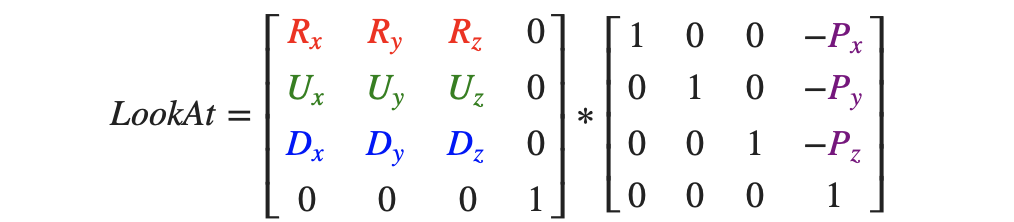
而glm的库给我们提供了现成的函数来生成View矩阵,也就是说我们只需要提供一个camera的位置,一个camera的指向target,以及一个Up向量,我们就可以直接构造出View矩阵1
2
3
4glm::mat4 view;
view = glm::lookAt(glm::vec3(0.0f, 0.0f, 3.0f),
glm::vec3(0.0f, 0.0f, 0.0f),
glm::vec3(0.0f, 1.0f, 0.0f));
如果我们想让我们的相机动起来,我们可以动态改变相机的位置。
通过上面的内容相机只能移动位置,而不能转向,这极大的限制了camera的能力,也与真实世界的场景不符,因此需要引入新的概念来表示相机的运动形态。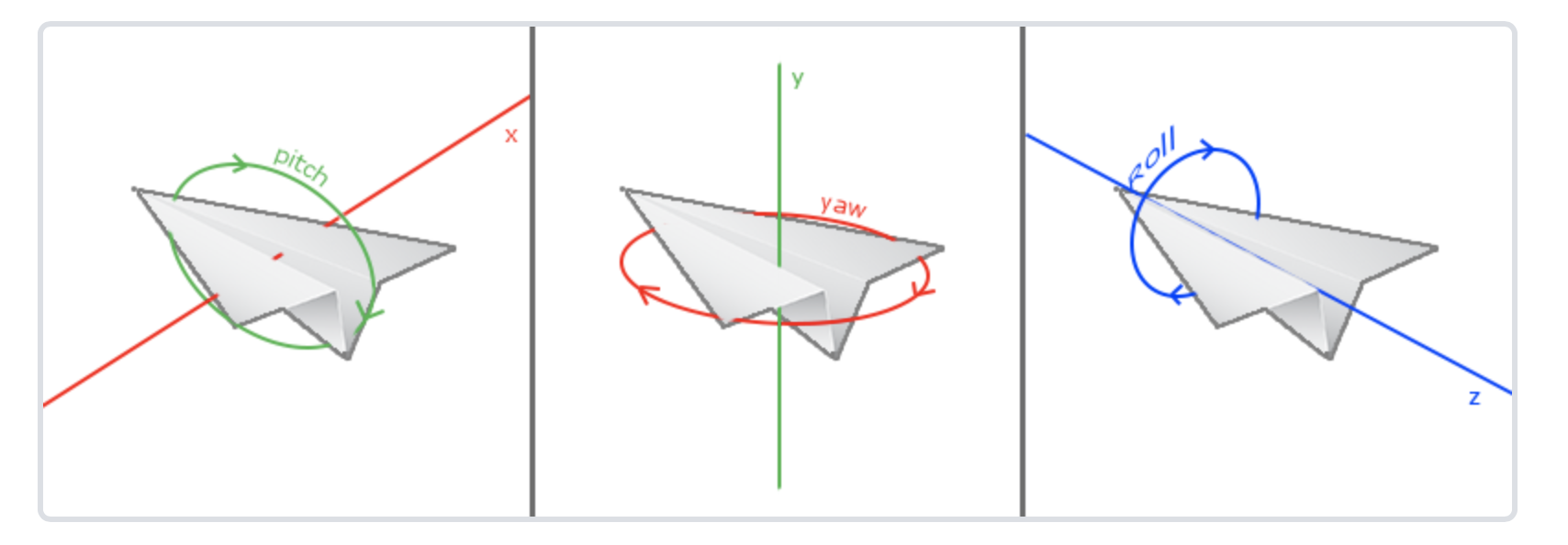
上面分别表示俯仰角,偏航角以及滚转角。(飞机飞行常用到这三个角)。在相机运动中,我们常用到前两个角度,也就是俯仰角以及偏航角。这些可以通过三角函数的知识来解决,这里不再论述,可以通过下面的链接学习:
https://learnopengl-cn.github.io/01%20Getting%20started/09%20Camera/
参考资料:
https://learnopengl-cn.github.io/01%20Getting%20started/09%20Camera/