引言
最近在搞GPU,往简单了说,GPU实际上就是在画三角形,往复杂了说,他的各种并行操作,各个渲染阶段几本书都讲不清楚。这大概也就是为什么能做好GPU的整个星球上也没有几家的原因吧。本文我们尝试从简化的架构来了解一下GPU的各个模块以及相应的工作原理。
首先先抛个图,下图就是Nvidia Turing102 GPU的一个组件架构图,可以看到密密麻麻的SM和RT Core,这两个组件实际上算是GPU的一个基本的工作单元,当然RT Core是引入光线追踪后出现的单元,早期的一些架构是不存在这一单元的。下图不是很清晰,可以查看NVIDIA-Turing-Architecture-Whitepaper来获取更加清晰的图像。

下面我们开始从逻辑渲染管线,以及架构图的各个组件的功能开始,一步一步的来解析GPU的架构逻辑
GPU的逻辑管线
现在GPU的发展,早已经不是最初的几个硬件实现一下加速功能而已,它有着复杂的逻辑,因此希望开发者按照GPU的物理管线进行编程是不现实的,同时由于水平以及理解的差异,必将导致效率良莠不齐,因此GPU实现了一套逻辑的管线,开发者只需要按照逻辑管线的规则进行操作即可。
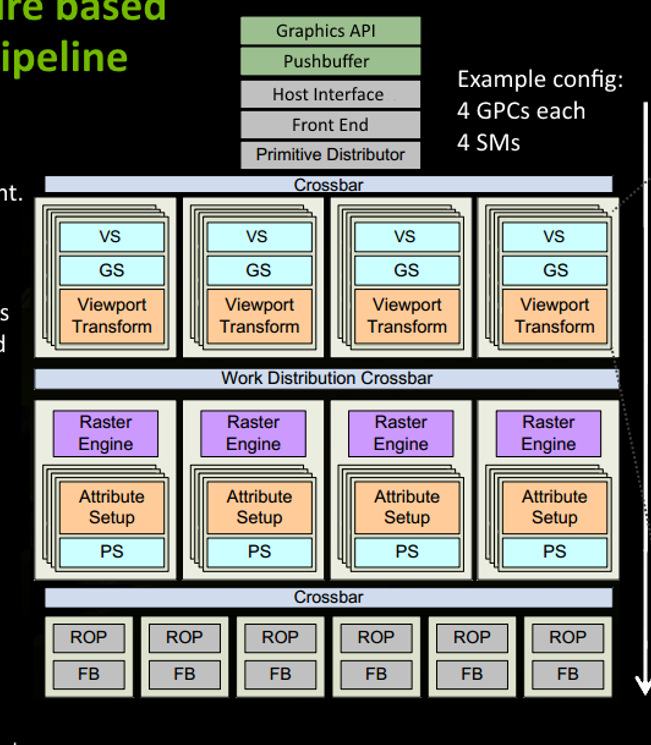
- 当我们需要渲染时,我们实际上会给GPU下一些指令,比如drawCall/bindBuffer等等,这些指令都属于Graphics API。
- 驱动程序则会将这些API编码到pushBuffer中。
- 当我们显示掉哟个flush或者pushBuffer指令积攒到一定时,驱动会批量将pushBuffer中的指令传送到GPU。
- GPU的Host Interface会拾取这些指令,然后交由Front End来处理
- Primitive Distributor负责分配任务,什么任务呢?就是将三角形分配给各个GPC(这里我们先不必理会GPC是什么)
- Crossbar来进行GPC之间的工作转移以及其他单元的通信,比如ROP(Render Output Unit)
- 通过vs(vertex shader)和GS(Geometry shader)来进行shader的操作,然后做视口的变换(也就是viewport Transform)
- 随后光栅化器会做光栅化
- Attribute Setup保证了从vs来的数据经过插值后是pixel-shade是可读的
- PS用来做pixel shader(也叫做fragment shader), 用来给光栅化后的pixel着色
- ROP会做blend,depth test等操作,保证最终的着色结果正确,然后将渲染结果输出到FB(FrameBuffer)
上面就是GPU渲染的一个逻辑工作流程。
GPU的架构以及相应的组件
还是从我们最开始的那张架构图说起
- PCI Express Host Interface 是主机与GPU的接口,用于主机与GPU的通讯交互
- GigaThread Engine 负责GPU所有工作的管理
- Memory Controller 两侧的12个存储控制器用来管理显存,它连接着L2 Cache和ROP unit, 下图中的蓝色小框就是ROP unit

GPC 在图中我们可以看到一共有6个GPC,GPC是Graphics Processing Cluster,图形处理簇,具体的图形渲染业务就是在GPC中进行。我们也能看出来,复杂的unit都在GPC中呢。

- 每个GPC里面有一个光栅化引擎,这个是用来做光栅化的
TPC 纹理处理簇, 每个GPC包含有6个TPC
- PolyMorph Engine 多边形引擎,它负责属性装配(attribute Setup)、顶点拉取(VertexFetch)、曲面细分
- SM(Streaming Multiprocessor) 流处理器, shader的执行就是在SM上进行的。这是一个非常重要的组件,下面我们会主要分析
PolyMorph Engine 多边形引擎
实际上这个里面包含了多个组件,如下所示:
- vertex Fetch 负责顶点获取
- Tessellator负责曲面细分
- viewport Transform负责视口变换
- Attribute Setup负责属性装配
- stream Output负责输出
SM(Streaming Multiprocessor)
这里我们单拿出来SM来分析,因为SM内部也是很复杂的,也有很多不一样的东西,下面是SM的结构图
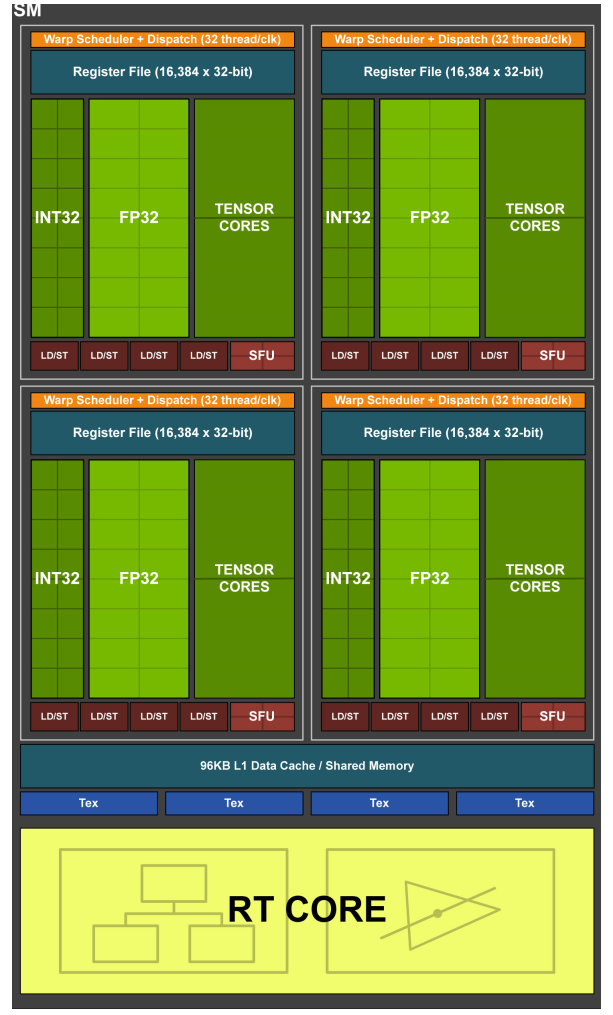
- Warp Scheduler 用来管理Warp(先不用管这是啥,下面会解释)
- Dispatch Unit 用来执行指令
- Register File 用来存储Register
- INT32 用于整形计算的core
- FP32 用于浮点数据的计算core
- Tensor Core 用来做矩阵运算的,在深度学习中会加速运算
- LD/ST(Load/Store) 也就是读取单元
- L1 Cache L1缓存
- Tex 纹理读取单元
- RT Core 光线追踪的,这里暂不介绍
- SFU(Special function units)执行特殊数学运算(sin、cos、log等)
下面我们来详细分析下SM:
我们知道GPU的运行逻辑是SIMD(Single Instructure Multiple Data),这就是在SM中实现的。SM中有很多的core,这些core可以执行计算。SM就负责Shader的执行。
SM从GigaThread Engine接收到大线程块,然后将其拆分为更小的堆,每个堆包含32个线程,这样的堆就被称之为Warp。一个Maxwell架构的SM最多可以容纳64个Warp。对于Maxwell的GPU, 一个SP(SMM)有4个Warp Scheduler, 每个Warp Scheduler可以处理一个Warp,并管理SM上剩余的Warp。

对于每个Core来说,它是不认识shader的,它每次只能看到一条指令,而且是32个core只能同时看到同一条指令。因此SM会给32个core下发同一条指令,所有的core均执行这提供一条指令,但是分配到不同core上的顶点数据可是不一样的,这样如果shader中存在if条件的话,就有可能存在一部分core在执行,一部分core在休息的场景。因此在shader中,if的存在对于并行度来说是个极大的挑战。
不可能存在说一部分 Core 在执行指令 A 的时候,另一部分 Core 却在执行指令 B。这种执行机制被称为 锁步(lock-step),这也是GPU的基础。
总的来说SM负责shader的执行,它接受指令,利用锁步(lock-step)机制,实现指令的并行处理。
还有一点,我们的Maxwell的SP明明只能同时执行4个Warp,为何还要一个让其容纳64个Warp呢?
这是因为有时候为了等待某些数据就绪,你不得不停下来。比如说,我们需要通过法线纹理贴图来计算法线光照,即使该法线纹理已经在 Cache 中了,访问该资源仍然会有所耗时,而如果它不在 Cache 中,那就更加耗时了。用专业术语讲就是 Memory Stall(内存延迟)。与其什么事情也不做,不如将当前的 Warp 换成其它已经准备就绪的 Warp 继续执行。
最后我们看下SM的变迁:

可以发现从Fermi, Kepler到Maxwell,SM的计算核心core的数量一直在增加,这也就意味着算力的提升。但是我们也可以发现,实际上这三个产品并没有架构上的提升,享受的一直是摩尔定律的红利。
但是Turing架构就不一样了,它引入了tenser Core和RT core,带来了架构的较大变迁。
Nvidia TU102 GPU的规格
- 4,608个CUDA Cores
- 72个RT Cores
- 576个Tensor Cores
- 288个texture units
- 12个32-bit GDDR6 memory controllers (384-bits total)
参考资料
http://simonschreibt.de/gat/renderhell/
https://developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline
NVIDIA-Turing-Architecture-Whitepaper.pdf