GPU一般来说有两种渲染模式,一种是IMR(Immediate Mode Rendering),一种是TBR(Tile Based Rendering)。巧了,这两种模式分别对应的是PC和mobile GPU,就像世上没有无缘无故的爱,也没有无缘无故的恨一样,PC和mobile选择了不同的渲染方式,必然是有其内在的本质原因的,下面我们就来分析一下。
IMR
最早的GPU都是直接渲染的,也就是提交一个primitive,pipeline就渲染一个primitive。每个core只需要render分给它的primitive就行,这样并行化起来,没有其他的控制逻辑,效率很高。
在fragment shader后对每个Raster出的pixel做一下排序即可(排序的目的是因为fs后会做blend等操作,因此需要排序。注意这里的排序跟sort-last里面的排序不是一个概念,sort-last里面的排序是来分仓的,这里是为了做blend的)

简单有时候也就意味着它有些一些缺点(否则人们就不用提出别的方法了)。
带宽和功耗较大
- z test跟blending都要频繁从framebuffer里读数据,毕竟framebuffer是位于Memory上,带宽压力和功耗自然高;
- overdraw的问题,比如在一帧里先画了棵树,然后画了面墙刚好遮住了树,在IMR下树仍然要在fragment Shader里做采样,而Texture也是放在Memory,访存功耗大
对于PC来说,上面的两点是可以忍受的,毕竟电池大,扇热也好解决,但是对于mobile就跪了,因此对于PC端,提出了TBR的渲染方式
TBR
TBR就是Tile-based rendering。也就是切片。既然带宽压力大,那么我们就在片上加一块on-chip缓存(当然这块缓存不会很大,更不可能是full screen sized),我们先将渲染的场景切块,然后渲染on-chip大小的区域,当把这块缓存渲染好了,我们再一次性的将其输出到frameBuffer上。这样就不用频繁从framebuffer里读/存数据,也就解决了带宽和功耗的问题。

我们具体看下TBR是怎么做的
在IMR中我们可以先draw red triangle,然后再draw green triangle, 然后再draw gray triangle。三个triangle之间有覆盖也没有关系,一个一个draw就好了,最多是有些overDraw的问题。
那么当我们用TBR的时候呢?我们首先将所有的primitive做sorting,然后将Screen分块(tile),tile1包含了red的一部分和green的一小部分,我们将其直接渲染到on-chip buffer上,当rasterization完成后,将on-chip buffer写入到framebuffer中,这样一个tile只需要写一次framebuffer。
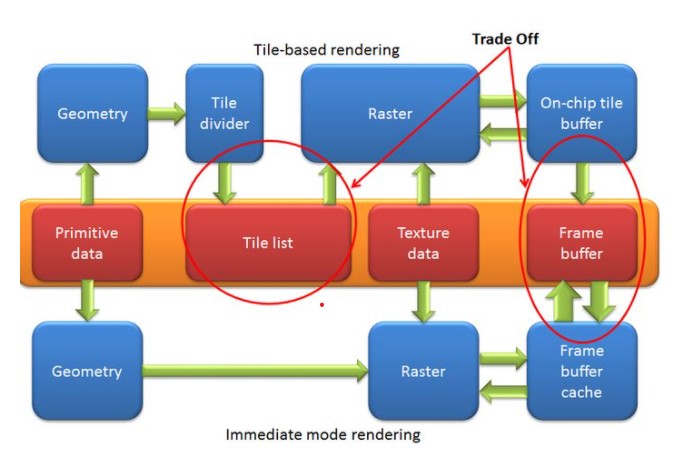
在IMR中我们直接做了光栅化,但是在TBR中是不行的,因为我们首先需要渲染一个on-chip大小的区域,那么这也就意味着我们需要提前排序,要挪到Rasterization前面(这实际上就是sort middle, IMR是sort last),因为只有将Triangle排序完,我们才能知道那些Triangle落在了我们指定的这个区域内,这样我们才能做on-chip的操作。
当然,哪有之占便宜不吃亏的好事,TBR也有问题。
- IMR的pipeline畅通无干扰,sorting简单,TBR的sorting较复杂,但也给低功耗优化提供了灵活的选择
- TBR pipeline的分割让pipeline中断了,各种defer,跟IMR比起来,速度也可能会进一步被影响而变慢。
参考资料:
https://www.zhihu.com/question/49141824/answer/136096531