引言
我们知道GPU是并行处理的利器,并行可以极大的提升效率。如果一个芯片只有一个core,那么同一时间,它只能处理一个任务,如果有两个core,并且他们能够并行解决问题,那么就能处理两个任务了,效率提升两倍(理想状态下,实际上是达不到的)。那么是不是核心越多,并行越多,效率就越高的?原则上是,但是实际上这是个渐进平缓的曲线,当核心越多时,调度就越复杂,同时单位芯片面积上也不能无限制的增加核心数目。因此,当核心数目达到一定时,再增加核心的数目,性能的提升已经很有限了。在业界,有个Amdahl’s Law用来描述这一现象。
$ a(s, p) = \frac{1}{s + \frac{1-s}{p}} $
其中s表示串行比例,p表示处理器个数。可见随着处理器核数的增加,性能的提升是越来越缓慢的。
GPU的渲染流程
下面我们来看下GPU的一个粗粒度的渲染流程,它主要有四部分
- Application
一般是在CPU上操作,负责数据的解析,视锥的剔除,BUffer的生成,API的调用等等 - Geometry
负责多边形及其顶点的大部分操作,包括vs,projection, clipping, Screen mapping, Tessellation, Geometry shader等操作 - Rasterization
只负责光栅化 - Pixel Processing
pixel shading 以及后续的blending等操作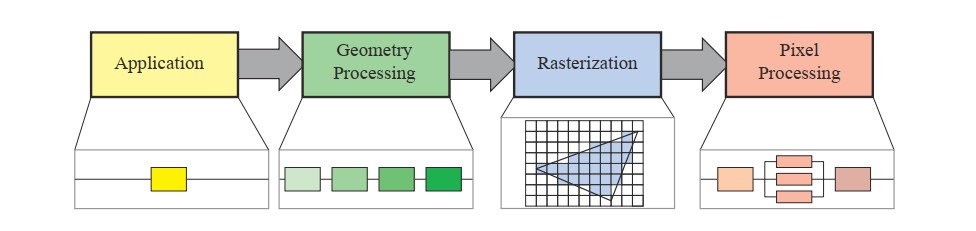
粗粒度的划分,GPU需要至少四个步骤,我们知道GPU是有多个核心的,是可以并行起来的。当我们需要画10000个三角形时,GPU是怎么分配任务的呢?同时这些三角形要按照规则画到一个屏幕上去,这么多核心要怎样配合呢?
为了解决上面的问题,人们提出四种架构模型,正好对应了上面的四个阶段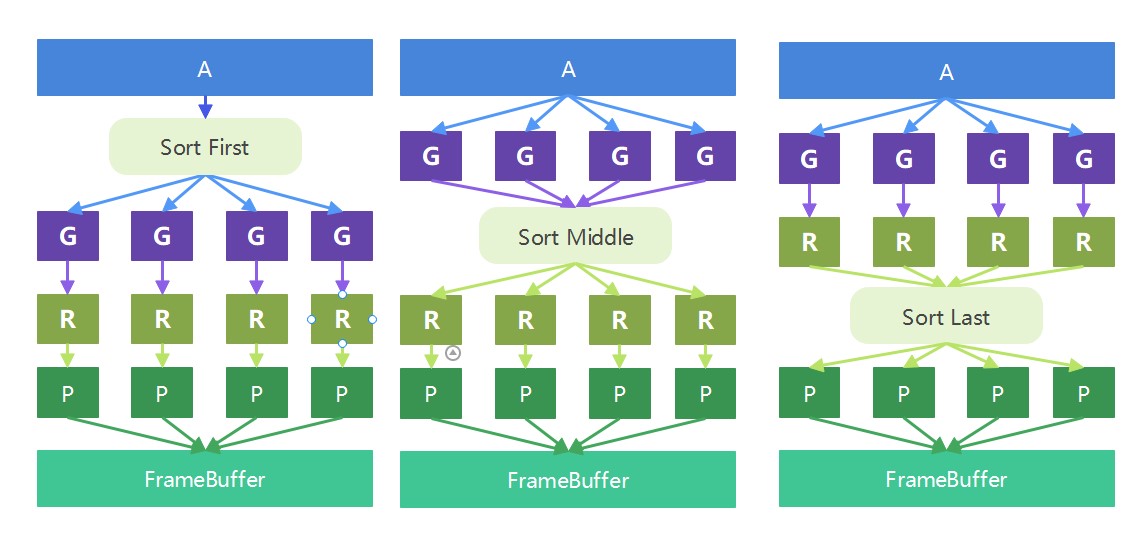
实在是盗不到图了,所以自己画了一个。这里少了一种模型,也就是在Pixel shader后面做排序的模型,这种基本没有用过,所以就不展示了。
为什么要做sort
首先思考一个问题,我们为什么要做一个sort操作?
这是因为我们的GPU是并行操作的,在架构上,每个组件(G/R/P)实际上只是负责整个屏幕的一片区域。如果不这样划分,每个组件都负责全屏的处理,那么冲突以及并行就会有一些问题。
Sort-First
这个模型也是比较少见,应该没有相关的硬件采用这种架构(或者是有,但是及其少见)。这个模型在raw data阶段就首先做了排序,这样给到Geometry Processing模块的数据就是已经排好序的了,它会将屏幕划分为一组区域,将区域内的primitives发送到负责该区域的pipeline上即可。
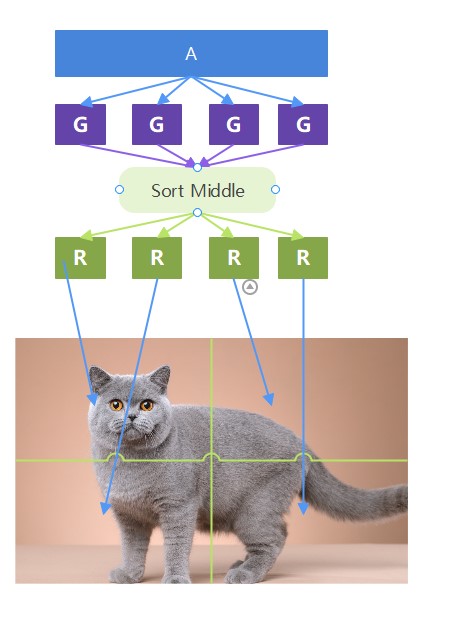
Sort-middle
对于sort-middle模型 ,假设我们Application下发的任务是画10K个Triangle,那么在Geometry Processing模块,任务是随机分配的,也就是如果我们有4个Geometry Processing模块,那么每个Geometry Processing模块需要处理2500个Triangle任务。当Geometry Processing模块处理完成后,我们就要对生成的Triangle进行排序了,这里的排序实际上是将Triangle按照它的位置分配给4个Rasterization模块(每个Rasterization模块负责屏幕上的不同区域)。然后同样的,对于Pixel Processing模块,它也只需要处理负责的区域的pixel着色即可。
如果Triangle覆盖了多个区域呢?那么它会被多个R/P进行处理。
Sort-last
sort-last也就意味着它的Geometry Processing模块以及Rasterization模块都是任务随机分配的。同样的对于Application下发的任务是画10K个Triangle,每个Geometry Processing模块需要处理2500个Triangle任务,处理完成后,每个Rasterization模块也随机分配到了2500个Triangle的Rast任务。这里每个Rasterization模块的渲染范围就是整个屏幕区域了。也就是说Triangle在哪,Rasterization模块就要Rast哪里。当做完所有的Rast操作后,再去sort,这样pixel阶段,就可以处理自己的区域了。
在R之后进行排序,那么也就意味着对于pixel shader来说,不会存在重叠的shader操作了,每个pixel位置的值只能是一个了。
另一种sort-last
还有一种架构,也就是在做完pixel shader后,再进行排序。这种架构也算比较奇怪了。再这种架构中,pipeline是独立的,再最后的合成阶段,所有的图像会根据z-buffer进行最终的合并。
IMR和TBR
上面的sort-middle和sort-last正好对应了两种不同的渲染模式TBR和IMR。这两种渲染模式也是手机端和桌面端GPU的两种架构。
我们看sort-middle在R阶段之前做了排序,那么Rasterization/Pixel shader/ROP都可以明确的知道自己操作的区域了,这就给TBR提供了架构上的支持。
我们知道TBR实际上就是sort-middle + on-chip Cache。
而IMR则是使用了sort-last架构。
为什么sort-last不能加on-chip Cache呢?
- sort-last的R是全屏幕空间,这个可不是一个固定值,即使是固定值,你也很难将它on-chip化,太大了。
那么桌面端为什么不能使用TBR呢?
- sort-middle在R之前进行了sort,那么这个sort结果呢?实际上是存在了ddr里面,如果我们的Triangle数量少还好说,如果数量多的话,这个操作的带宽和速度可不一定比sort-last好到哪里去。而桌面端的画质要求Triangle的数量可不是手机端能比的。因为对于手机端,这个数量可控(毕竟屏幕就那么大,能画多少Triangle),因为收益是大于付出的。
因此如果桌面端用了TBR,那么才是好处没捞着,坏处全占了呢。
sort-middle和sort-last的负载不均衡问题
所以我们看对于sort-middle来说,他的R阶段负责是不均衡的,因为可能这10K个三角形有9K都在左上角,那么一个R模块就需要做大量的光栅化,而其他的三个R就很轻松。但是对于sort-last来说,每个R分配了相同的任务两,但是对于P阶段来说,它就是负载不均衡的了。所以说负载不均衡是普遍存在的,只不过是在那个阶段罢了。
参考资料
A sorting classification of parallel Rendering. molnar 1994.