GPU不仅可以用来渲染,也可以用来做通用计算。实际上渲染操作也是一系列的运算,进而得到最终的输出颜色结果。在NPU出现之前,GPU一直是神经网络的利器。GPU是高度并行化的器件,因此用GPU来进行并行计算,将会极大的提升效率。
Vulkan也提供了计算管线用来实现GPU的计算功能。
work group
计算着色器运行在一个抽象的3维空间中。这个空间被称为工作组(work group);这是用户可以执行的最小计算操作量。或者换句话说,用户可以执行一定数量的工作组。工作组是计算着色器的基本内容。
首先在compute shader中最小的一个执行单元为:
Thread也称作Invocation
shader执行一次main函数,也就算是一次Invocation

local work group
而GPU在执行的时候是以一个work group的形式来执行的,也就是每次会下发一批的任务,这个就被称作local work group,也就是本地工作组。
本地工作组的大小需要在shader中指定,例如下图中的local work group的设置应该为:
1 | layout (local_size_x = 5, local_size_y = 3, local_size_z = 1) in; |
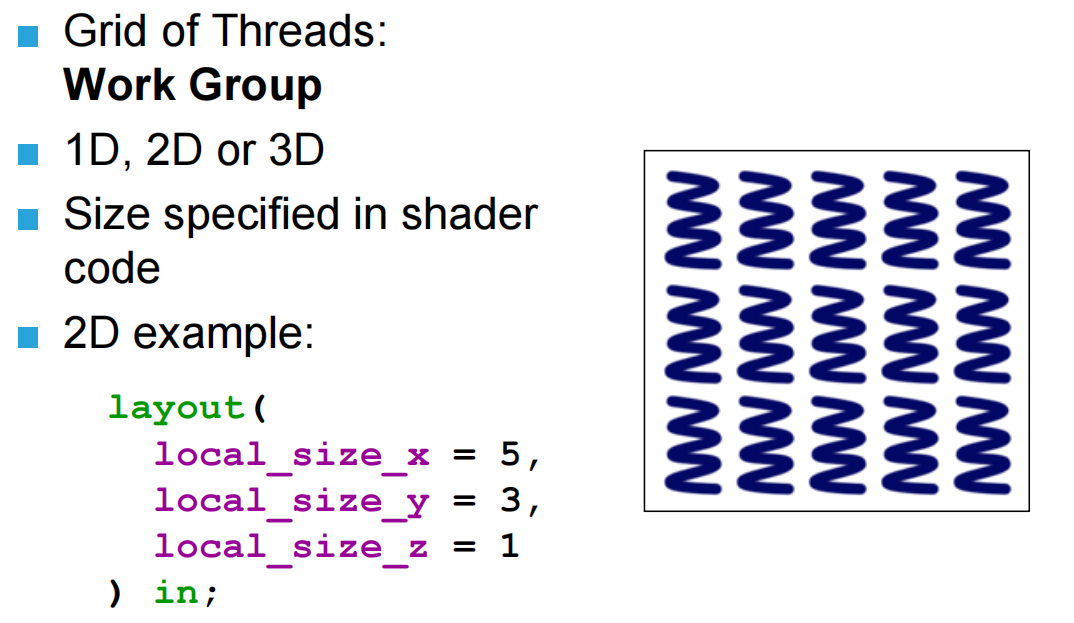
虽然图中是二维的,但是local work group可以设置为1D/2D/3D的。
global work group
而一次vkCmdDispatch调用则会下发一个完整的global work group,这是命令执行的一个单位。global work group实际上就是包含了一组的local work group,如下图所示:
在vulkan中,有如下的命令:
1 | vkCmdDispatch(commandBuffer, 4, 8, 1); |

如何设置local work group的大小
上面讲了各种work group的概念,那么我们可以看到在shader中需要设置local work group,并且在中,也要根据local work group的大小设置local work group的数量,那么如何设置local work group的大小呢?也就是shader中的
1 | layout (local_size_x = 16, local_size_y = 16) in; |
实际上这个值是实验设定的,也就是说一般情况下设置为任何值皆可,但是local work group的大小是会影响到最终的运行时间的,因此一般需要通过实验求得。
当然为了修改方便,这个值也可以通过代码传入,如下所示:
1 | layout( local_size_variable ) in; |
当然上面说的是一般情况下,在某些特殊情况下,比如存在依赖的场景,那么这个local work group的大小就需要根据实际设置了。
vkCmdDispatch
计算管线使用vkCmdDispatch进行计算任务的下发执行
1 | VKAPI_ATTR void VKAPI_CALL vkCmdDispatch( |
它一共有四个参数:
1 | commandBuffer is the command buffer into which the command will be recorded. |
每个vkCmdDispatch对应一个global work group
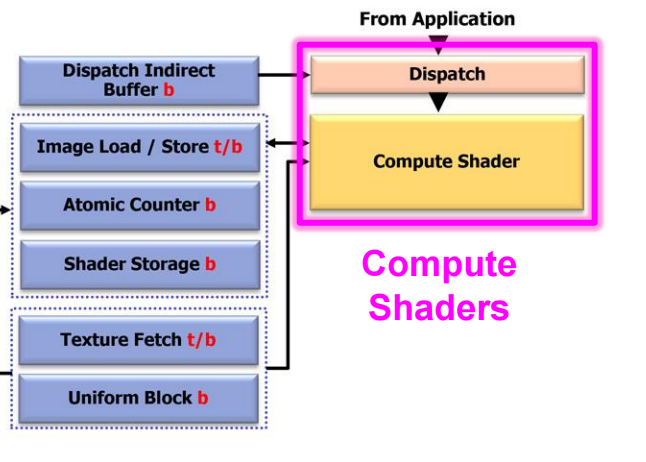
Compute Shader
compute shader在openGL4.3中被引入,是一个完全用于计算任务的stage,它通常用与与绘制三角形和像素无关的任务,比如图像处理,粒子运动等等。
compute shader在openGL的流程中如下所示:
计算管线的shader的命名如下所示:
1 | *.comp |
同样的需要编译为spv文件才能被加载运行。
相对于传统的渲染管线,一般来将,它有vertex Shader和Fragment Shader,用来从显存读取数据(利用location),然后将最终的渲染结果输出到Frame Buffer。然而对于Compute Shader,它没有location的输入,也没有Frame Buffer的输出。一个Compute Shader的输入输出都是通过描述符的形式(UBO,texture等资源)利用binding的方式进去读取,然后处理,处理后写出的。如下所示:
1 | layout (binding = 0, rgba8) uniform readonly image2D inputImage; |
同时对于Compute Shader,需要指定一个抽象的计算空间,在shader中需要明确如下:
1 | layout (local_size_x = 16, local_size_y = 16) in; |
local_size_x、local_size_y、local_size_z分别表示在3个维度上的本地工作组的大小,如果不写,默认为1。这个是必须要指定的。
GLSL built-in variables
glsl内置了几个变量用来在Compute Shader获取具体的位置数据,如下所示:

假设我们下发了上图的任务,那么红色的就是一个Thread,那么我们怎么获取到它的具体位置呢(假设是2D的)?其中:
gl_GlobalInvocationID获取Thread在全局工作组的位置,(0,0)点在左下方,则它的位置为(13,12,0)gl_LocalInvocationID获取Thread在本地工作组的位置,本地工作组会定位到途中的具体块,即为如下:
那么Thread在local work group中的值为(3,0,0)
gl_WorkGroupID为local work group在global work group中的位置信息,则为(2,4,0)
Compute Pipeline
计算管线的创建跟渲染管线的创建基本一致,只是需要调用下面的接口
1 | VKAPI_ATTR VkResult VKAPI_CALL vkCreateComputePipelines( |
Shader Storage Buffer Object
在Compute Shader中,我们没有办法拿到纹理坐标,也不是做纹理采样,因此我们创建的资源也不是纹理采样器,而是Storage Buffer。
- shader中的image2D
因此在shader中,我们有如下的资源设置:
1 | layout (binding = 0, rgba8) uniform readonly image2D inputImage; |
image2D表示我们需要的是图片而不是采样器,我们使用像素坐标来获取像素颜色值,而并不是通过纹理坐标采样颜色值。
使用 readonly 表示这张图片我们只会读取(image load)它而不会去将数据写入(image store)它。
VkImageCreateInfo
在创建图像资源时,因为我们的图像要用来做通用计算,因此我们需要将其设置为:VK_IMAGE_USAGE_STORAGE_BIT
同时如果这个图像如果还要在后续的渲染流程中使用,则需要将其设置为:VK_IMAGE_USAGE_SAMPLED_BIT
1 | VkImageCreateInfo imageCreateInfo = vks::initializers::imageCreateInfo(); |
- VkDescriptorSetLayoutBinding
在描述符集中需要将资源格式设置为VK_DESCRIPTOR_TYPE_STORAGE_IMAGE
1 | VK_CHECK_RESULT(vkAllocateDescriptorSets(device, &allocInfo, &compute.descriptorSet)); |
同样的在Pipeline Layout中也需要修改格式为VK_DESCRIPTOR_TYPE_STORAGE_IMAGE
1 | std::vector<VkDescriptorSetLayoutBinding> setLayoutBindings = { |
Synchronization
在经典的图像处理例子中,我们首先要利用计算管线对图像进行处理,然后再利用渲染管线将其输出,那么这就会遇到一个同步问题:
我们要保证渲染要在计算完成后执行
但是由于GPU的管线是并行的,渲染管线拿到的图像很有可能是计算管线还没有处理完的半成品,因此需要同步机制来确保这个先后顺序。
- 利用
semaphore来确保命令的提交顺序
1 | void draw() |
- 利用Barrier来确保资源的读取与写入顺序
由于我们需要在计算管线写入完图像后,在利用渲染管线将图像输出,因此需要在图形管线的commandBuffer提交前设置Image Memory Barrier。如下所示:
1 | // Image memory barrier to make sure that compute shader writes are finished before sampling from the texture |
其中:
srcStageMask为VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT,
dstStageMask为VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT
srcAccessMask 为 VK_ACCESS_SHADER_WRITE_BITdstAccessMask 为 VK_ACCESS_SHADER_READ_BIT
Compute Shader vs Graphic Shader
渲染管线的fragment shader也可以对图像进行处理,那么为什么还要引入Compute shader呢?
一个原因是渲染管线在着色后还有ROP等操作,这些操作对图像处理是不需要的,简化了这些流程能较大的提升GPU的处理性能。
参考资料
https://www.khronos.org/opengl/wiki/Compute_Shader
https://www.cg.tuwien.ac.at/courses/Realtime/repetitorium/VU.WS.2014/rtr_rep_2014_ComputeShader.pdf
Microsoft PowerPoint - kite.compute.shader.pptx (khronos.org)
《OpenGL编程指南(原书第8版)》——计算着色器 - 知乎 (zhihu.com)
OpenGL4.3新特性: 计算着色器 Compute Shader - 知乎 (zhihu.com)
OpenGL-Executing Compute Shaders - 知乎 (zhihu.com)
OpenGL/OpenCL中的gl_GlobalInvocationID, local_size_x的理解 | 码农网 (codercto.com)
GitHub - SaschaWillems/Vulkan: Examples and demos for the new Vulkan API